CIFAR-10
1.目录
首先,导入竞赛所需要的包和模块:
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
2.1 下载数据集:
#@save
d分类目录归档:深度学习
数据增广不仅用于处理图片,也可用于文本和语音,这里只涉及到图片。
采集数据得到的训练场景与实际部署场景不同是常见的问题,这种变化有时会显著影响模型表现。在训练集中尽可能模拟部署时可能遇到的场景对模型的泛化性十分重要。
数据增强是指在一个已有数据集上操作使其有更多的多样性。对语音来说可以加入不同的背景噪音,对图片而言可以改变其颜色,形状等。
一般来说不会先将数据集做增广后存下来再用于训练;而是直接在线生成,从原始数据中读图片
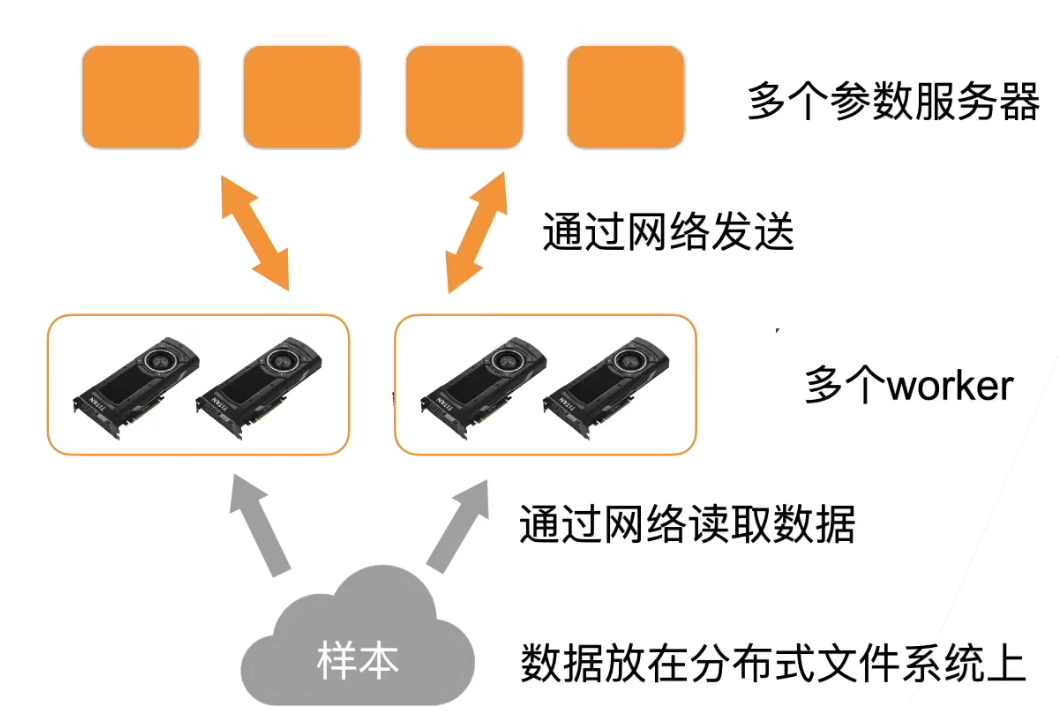
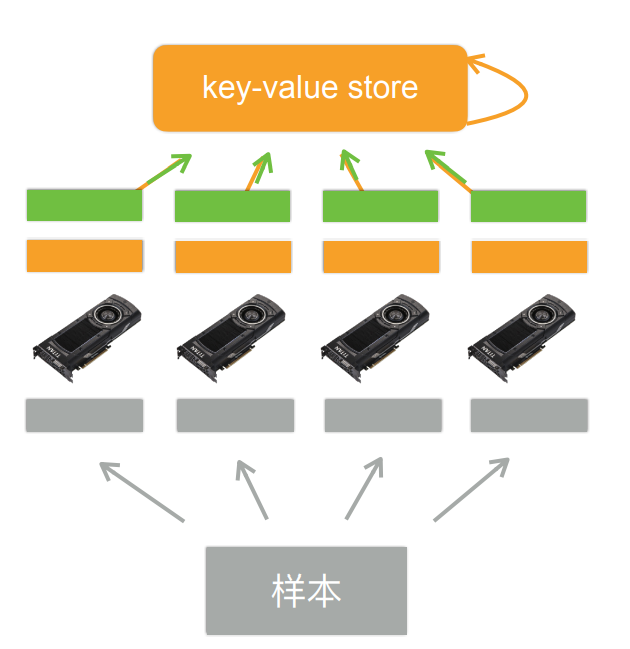
一台机器可以安装多个GPU(一般为1-16个),在训练和预测时可以将一个小批量计算切分到多个GPU上来达到加速目的,常用的切分方案有数据并行,模型并行,通道并行。
将小批量的数据分为n块,每个GPU拿到完整的参数,对这一块的数据进行前向传播与反向传播,计算梯度。
数据并行通常性能比模型并行更好,因为对数据进行划分使得各个GPU的计算内容更加均匀。
 主要分为五部
主要分为五部
本节我们介绍除了 GPU CPU 之外更多的芯片
为数字信号处理算法设计:点积、卷积、FFT
低功耗,高性能
主内存->L3->L2->L1->寄存器
深层神经网络的训练,尤其是使网络在较短时间内收敛是十分困难的,批量归一化[batch normalization]是一种流行且有效的技术,能加速深层网络的收敛速度,目前仍被广泛使用。
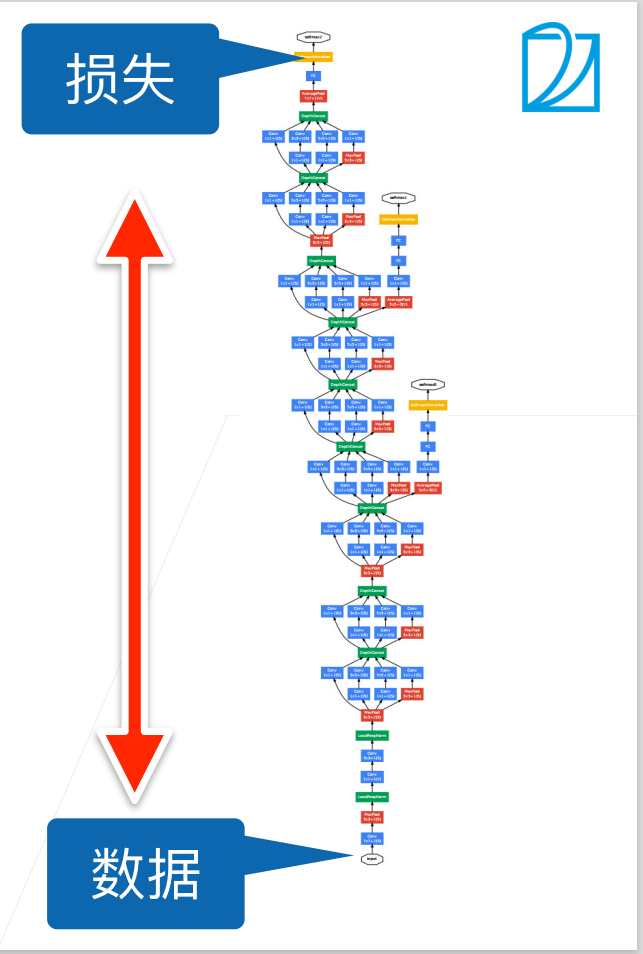
深度神经网络在训练时会遇到一些问题: