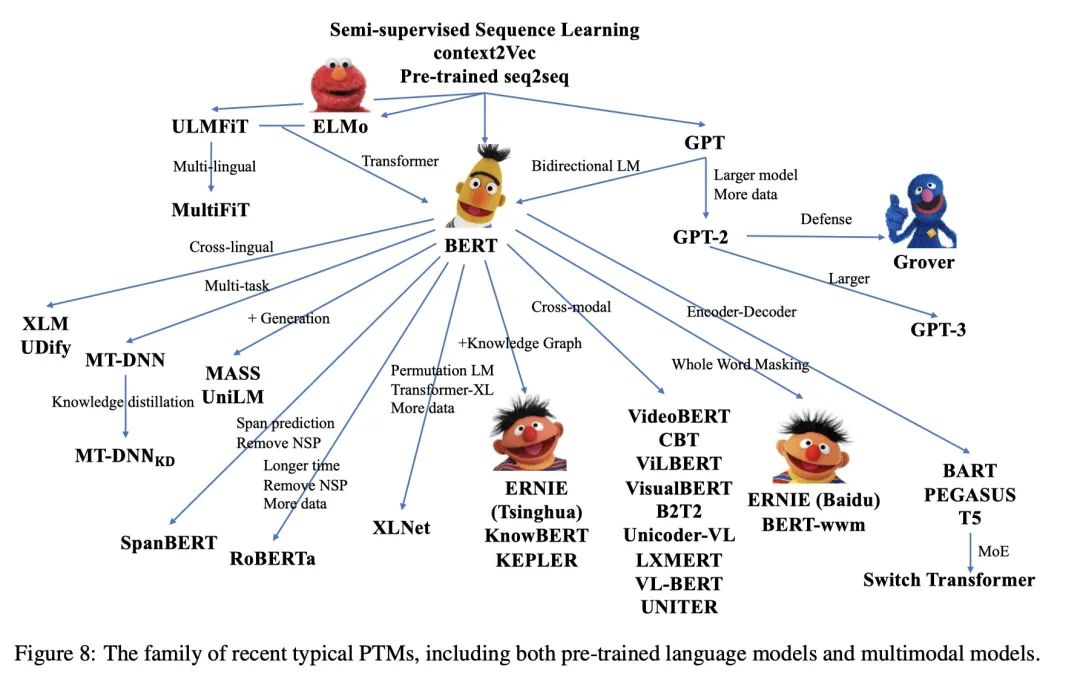
一切都得从 Transformer 说起。Transformer 左半边为 Encoder,右半边为 Decoder。我们将 Encoder 输入的句子称为 source,Decoder 输入的句子称为 target
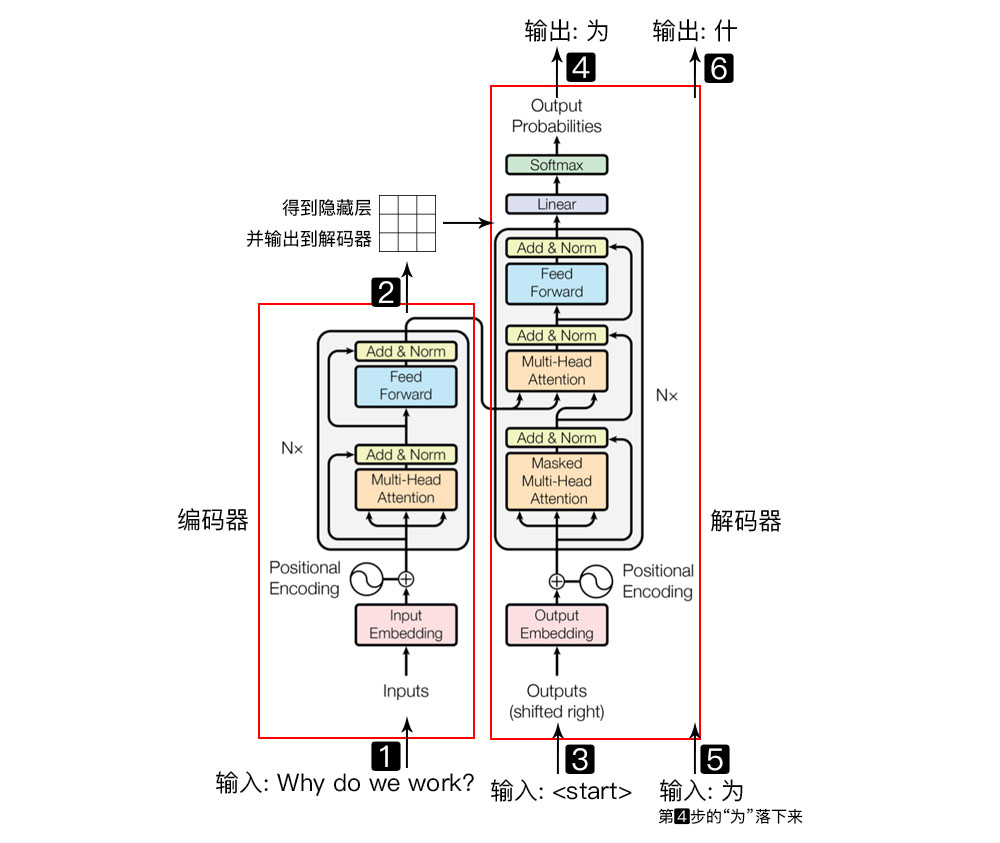
Encoder 负责将 source 进行 self-attention 并获得句子中每个词的 representation,最经典的 Encoder 架构就是 BERT,通过 Masked Language Model 来学习词之间的关系,另外还有 XLNet, RoBERTa, ALBERT, DistilBERT 等等。但是单独 Encoder 结构不适用于生成任务
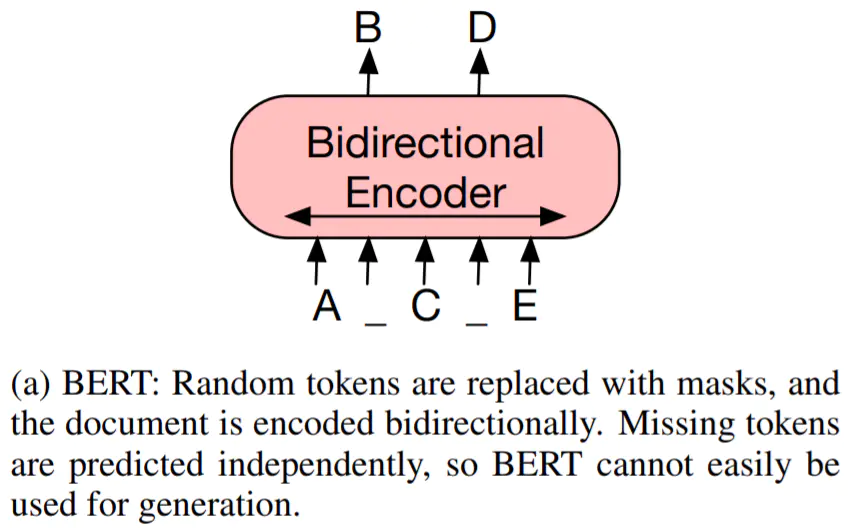
D

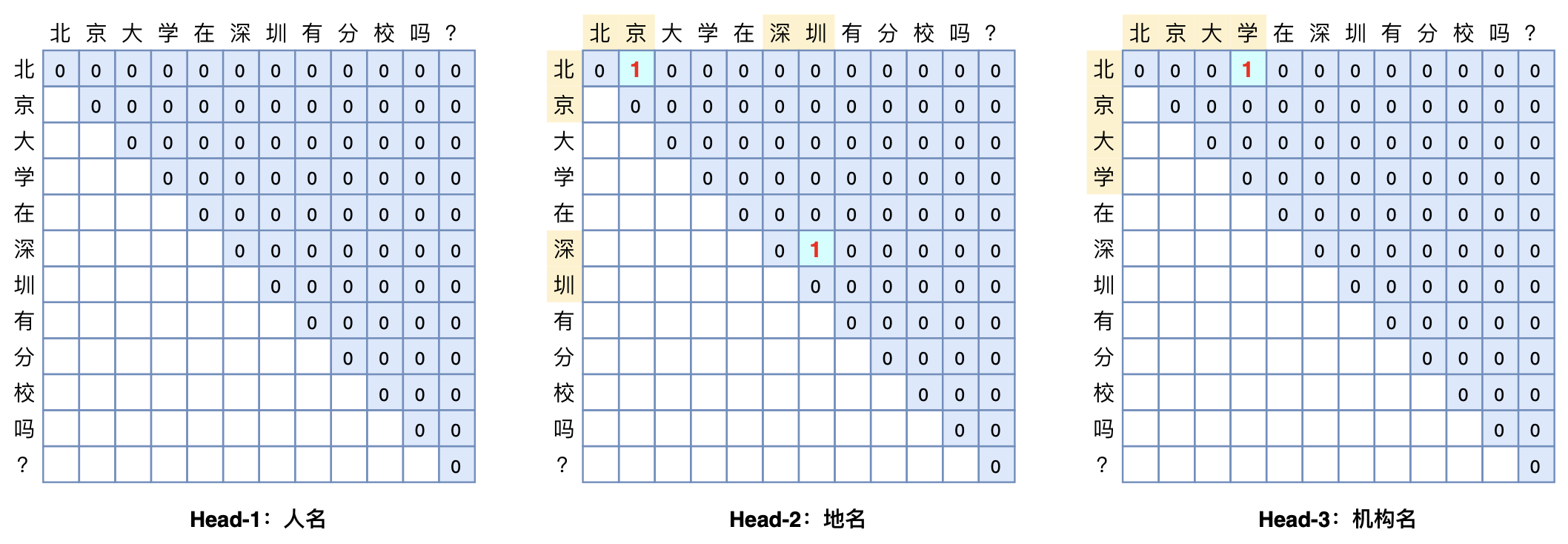 GlobalPoniter多头识别嵌套实体示意图
GlobalPoniter多头识别嵌套实体示意图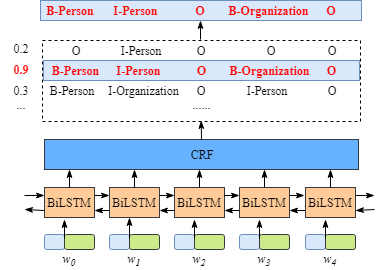
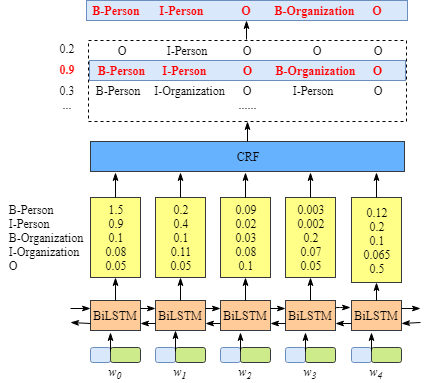
 image.png
论文地址:
image.png
论文地址: