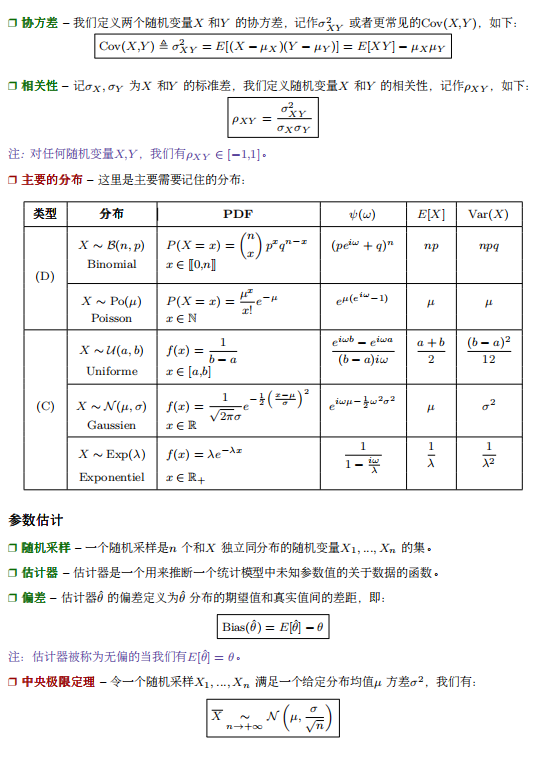
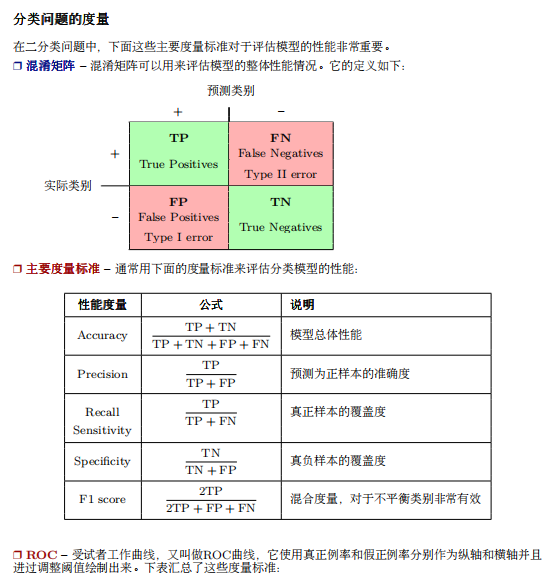
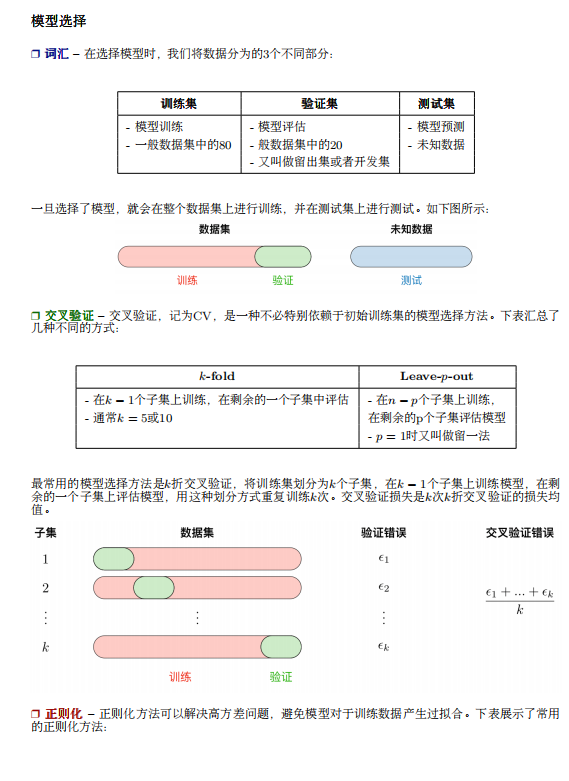
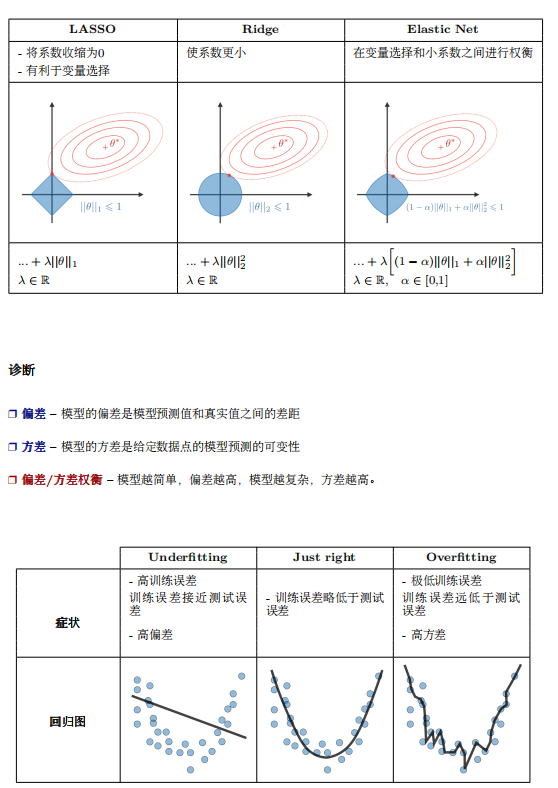
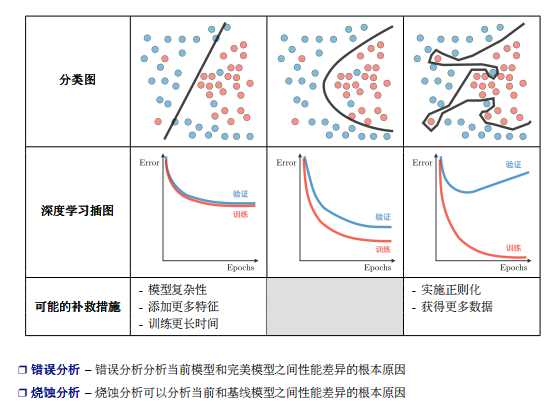
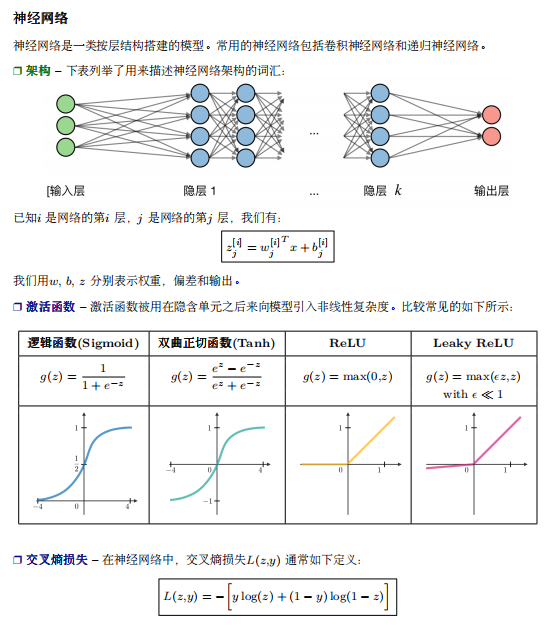
image.png
论文地址:https://arxiv.org/pdf/1907.11692.pdf
论文标题:
RoBERTa: A Robustly Optimized BERT Pretraining A pproach
一个强力优化的BERT预训练方法。
image.png
论文地址:https://arxiv.org/pdf/1907.11692.pdf
论文标题:
RoBERTa: A Robustly Optimized BERT Pretraining A pproach
一个强力优化的BERT预训练方法。
0、摘要:
语言模式预训练已经带来了显著的性能提升,但仔细比较不同方法是一个挑战。训练的计算成本很高,通常是在不同大小的私有数据集上进行的,我们将展示,超参数选择对最终结果有重大影响。我们对BERT 预训练进行了一项复制研究,仔细测量了许多关键超参数和训练数据大小的影响。 我们发现,BERT的训练明显不足,可以与发布后的每个模型的
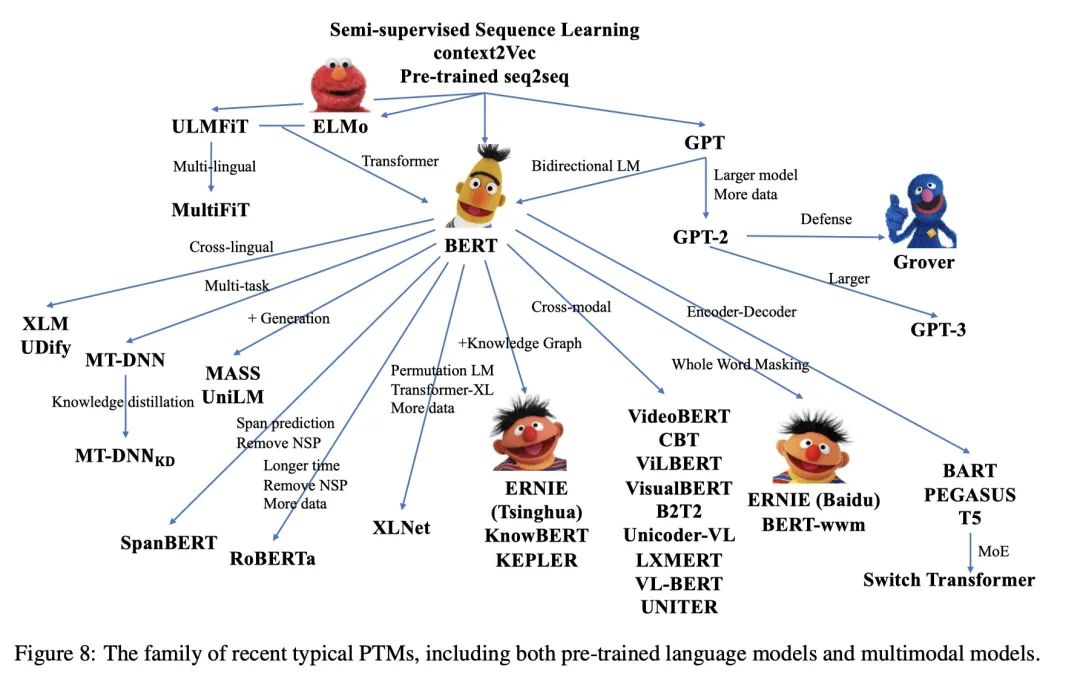
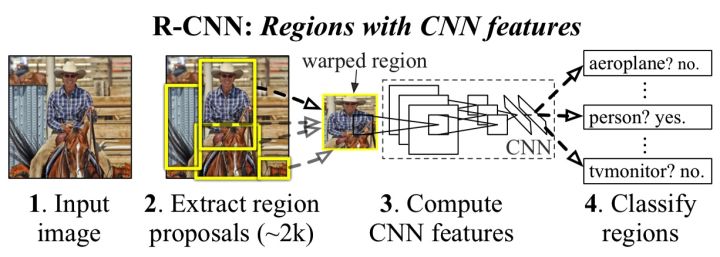 核心思想:
1.区域选择不再使用滑窗,而是采用启发式候选区域生成算法(Selective Search)
2.特征提取也从手工变成利用CNN自动提取特征,增
核心思想:
1.区域选择不再使用滑窗,而是采用启发式候选区域生成算法(Selective Search)
2.特征提取也从手工变成利用CNN自动提取特征,增