02-深度学习介绍
本节目录
1. 概述
1.1 AI地图
首先画一个简单的人工智能地图:

x轴表示不同的模式or方法:最早的是符号学,接下来是概率模型,之后是机器学习
y轴表示可以达到的层次:由底部向上依次是
感知:
分类标签归档:python
首先画一个简单的人工智能地图:
x轴表示不同的模式or方法:最早的是符号学,接下来是概率模型,之后是机器学习
y轴表示可以达到的层次:由底部向上依次是
感知:
本文是对CRF基本原理的一个简明的介绍。 我们先来对比一下普通的逐帧softmax和CRF的异同。
CRF主要用于序列标注问题,可以简单理解为是
给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
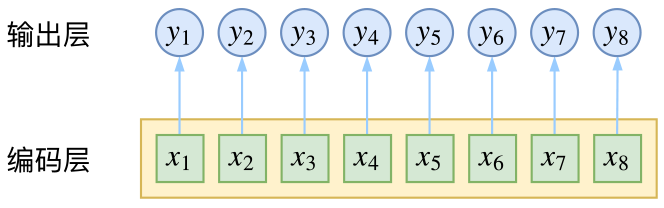
逐帧softmax并没有直接考虑输出的上下文关联
然而,当我们设计标签时,比如用s、b、m、e的4个标签来做字标注法的分词,目标输出序列本身会带有一些上下文关联,比如s后面就不能接m和e,等等。逐标签softmax并没有考虑这种输出层面的上下文关联,所以它意味着把这些关联放到了编码
上一篇Attention机制详解(一)——Seq2Seq中的Attention回顾了早期Attention机制与RNN结合在机器翻译中的效果,RNN由于其顺序结构训练速度常常受到限制,既然Attention模型本身可以看到全局的信息, 那么一个自然的疑问是我们能不能去掉RNN结构,仅仅依赖于Attention模型呢,这样我们可以使训练并行化,同时拥有全局信息? 这一篇就主要根据谷歌的这篇Attention is All you need论文来回顾一下仅依赖于Attention机制的Transformer架构,并结合Tensor2Tensor源代码进行解释。
先来看一个翻

通过post、get请求url,返回网页数据利用re或bs4进行解析即可,和我们平时部署接口请求接口差不多,这里不详述。
上面提到的requests模块更多是爬取静态网页,遇到动态网页,就需要这个爬虫利器selenium了。它的优点主要有: 当页面内容是由 JavaScript 动态生成,通过 requests 请求页面无法获取内容,而selenium可以。 requests 爬虫程序容易被反爬虫策略限制,selenium模拟鼠标键盘操作,让程序的行为和人一样,可绕过大部分反爬。
安装部署参考h
方案一:破解后有效期到2089年,但有版本要求,必须是2019.1及之前版本。 方案二:有效期只有几个月,需要到期后再找注册码激活,但没有版本限制。
window7、64位
Pycharm专业版2019.1(注意:最新版的2019.1.3方案一不能成功)
Pycharm旧版本下载地址:https://www.jetbrains.com/pycharm/download/previous.html
 选择version2019.1
选择version2019.1
安装pycharm过程不详说,但要记住安装路径。 安装完pycharm后下面开始正式破解
第一步:下载pycharm破解补丁 链接:https:
如果你想进入机器学习领域,循环神经网络是一种很重要的技术,需要理解。如果你使用智能手机或经常上网,你很有可能接触过利用 RNN 的应用程序。循环神经网络用于语音识别、语言翻译、股票预测;它甚至用于图像识别以描述图片中的内容。
RNN 是擅长对序列数据建模的神经网络。为了理解这句话的含义,我们来看一个小实验。假设你拍摄了一个及时移动的球的静止快照。
 图1
假设你想预测球移动的方向。那么只有你在屏幕上看到的信息,你会怎么做?你可以猜测一下,但你想出的任何答案都是随机猜测。如果不知道球的位置,就没有足够的数据来预测球的
图1
假设你想预测球移动的方向。那么只有你在屏幕上看到的信息,你会怎么做?你可以猜测一下,但你想出的任何答案都是随机猜测。如果不知道球的位置,就没有足够的数据来预测球的
人工神经网络是一门机器学习学科,已成功应用于模式分类、聚类、回归、关联、时间序列预测、优化等问题。随着过去十年社交媒体的日益普及,图像和视频处理任务变得非常重要。以前的神经网络架构(例如前馈神经网络)无法扩展用以处理图像和视频任务。这加速了专门为图像和视频处理任务量身定制的卷积神经网络的出现。在本篇文章中,我们将解释什么是卷积神经网络,讨论它们的架构,并用代码实现一两个简单模型。
在全连接 FNN(如下图所示结构)中,一层中的所有节点都连接到下一层中的所有
到目前为止,在本系列文章中,我们已经了解了神经网络如何解决回归问题。现在我们要将神经网络应用于另一个常见的机器学习问题:分类。就目前我们学到过的内容,大部分内容仍然适用。主要区别在于我们使用的损失函数以及我们希望最后一层产生什么样的输出。
二分类是一个常见的机器学习问题。您可能想要预测客户是否有可能进行购买、信用卡交易是否存在欺诈、深空信号是否显示出新行星的证据等等,这些都是二分类问题。 在您的原始数据中,类可能由诸如“是”和“否”或“狗”和“猫”之类的字符串表示。在使用这些数据之前,我们将分配一个类别标签:一个类别为 0,另一个类别为 1。分配数字
深度学习的世界不仅仅是dense层。您可以向模型添加数十种图层。(尝试浏览 [Keras]文档以获取示例!)有些类似于dense层并定义神经元之间的连接,而有些则可以进行其他类型的预处理或转换。 在本文章中,我们将了解两种特殊层,它们本身不包含任何神经元,但会添加一些功能,有时可以以各种方式使模型受益。两者都常用于现代模型结构中。
其中第一个是“dropout 层”,它可以帮助纠正过拟合。 在上一篇文章中,我们讨论了网络学习训练数据中的虚假模式如何导致过度拟合。为了识别这些虚假模式,网络通常会依赖于非常特定的权重组合,一种权重的“阴谋”。但是,它们往往很脆弱:删除一个,阴谋就会
回想一下上一篇文章中的示例,Keras 能保留它训练模型过程中训练和验证损失的历史记录,并且可以画出来。在本文中,我们将学习如何解释这些学习曲线以及如何使用它们来指导模型开发。特别是,我们将在学习曲线上寻找模型欠拟合(underfittiing)或者过拟合(overfitting)的证据,并查看几种防止过拟合或者欠拟合的策略。
我们可能认为训练数据中的信息有两种:信号(signal)和噪声(noise)。信号是概括的部分,即可以帮助我们的模型根据新数据进行预测的部分。噪声是仅适用于训练数据的那部分;噪声是来自现实世界中的数据的所